
Introducing Natural Language Processing

Hallo apa kabar semua, kembali lagi di website anazmtech membahas tentang segala teknologi pada IT khususnya matematika dan pemrograman. Pada kesempatan kali ini kita akan membahas materi dan series baru yaitu natural language processing. Untuk lebih jelasnya mari kita bahas di bawah ini.
Definisi Natural Language Processing

Natural Language Processing merupakan salahsatu bidang ilmu Kecerdasan Buatan (Artificial Intelligence) yang mempelajari Komunikasi antara manusia dengan komputer melalui bahasa alami. Model komputasi seperti ini berguna untuk memudahkan komunikasi antara manusia dengan komputer dalam hal pencarian informasi, sehingga dapat terjadi suatu interaksi antara keduanya dengan menggunakan bahasa alami. Setidaknya, ada dua fase utama dalam proses kerja NLP, yaitu pemrosesan awal data dan pengembangan algoritma.
NLP dasar memiliki tugas-tugas antara lain tokenisasi dan parsing, lemmatization/stemming, part-of-speech tagging, deteksi bahasa, dan identifikasi hubungan semantik. Secara umum, tugas NLP memecah bahasa menjadi potongan-potongan unsur yang lebih pendek, kemudian memahami hubungan di antara potongan tersebut, dan menjelajahi bagaimana potongan itu bekerja bersama untuk menciptakan makna.
Pemrosesan NLP
Pemrosesan awal data dalam NLP meliputi persiapan serta pembersihan data teks. Hal ini dilakukan untuk menempatkan data dalam bentuk yang dapat diterapkan pada algoritma. Sehingga, komputer dapat menganalisis data dengan baik.
Pemrosesan awal data dapat dilakukan dengan beberapa cara diantaranya adalah sebagai berikut :
1. Part of speech tagging
Part-of-speech (POS) tagging atau secara singkat dapat ditulis sebagai tagging merupakan proses pemberian penanda POS atau kelas sintaktik pada tiap kata di dalam corpus. Dikarenakan tag secara umum juga diaplikasikan pada tanda baca, maka dalam proses tagging, tanda baca seperti tanda titik, tanda koma, dll perlu dipisahkan dari kata-kata. Oleh sebab itu, proses tokenisasi biasanya dilakukan sebelum POS tagging. Selain itu beberapa preprocessing juga dilakukan seperti pemisahan koma, tanda petik, dll dari kata serta dilakukan juga disambiguitas pada tanda baca penanda akhir kalimat seperti tanda titik dan tanda tanya agar dapat dibedakan dari tanda yang digunakan untuk singkatan (seperti contohnya: e.g. dan etc.).
Seperti pernah disebutkan sebelumnya, masalah utama dalam melakukan tagging adalah ambiguitas terutama ketika kita meminta sistem untuk melakukannya secara otomatis. Contoh dari beberapa kata yang seringkali menimbullkan ambiguitas diantaranya adalah book dikarenakan memiliki 2 buah makna, yakni book sebagai kata benda yang berarti buku dan sebagai kata kerja yang berarti memesan. Oleh karena itu POS-tagging bertujuan untuk menyelesaikan masalah ini dengan memilih tag yang tepat untuk konteks kata di dalam kalimat.
Dalam konteks tagging di Bahasa Inggris, yang paling sering digunakan adalah Penn Treebank. Rinciannya terdapat pada gambar 1 di bawah ini.

Kebanyakan algoritma untuk tagging termasuk salah satu kelas dari rule-based taggers dan stochastic taggers. Rule-based tagger secara umum melibatkan database dalam ukuran yang besar mengenai aturan-aturan disambiguasi dari tulisan tangan yang menspesifikasikan diantaranya, sebuah kata yang ambigu adalah kata benda dan bukan kata kerja jika diikuti oleh determiner. Salah satu contoh rule-based tagger adalah EngCG, yang berdasarkan arsitektur Constraint Grammar dari Karlsson et al (1995).
Stochastic taggers secara umum menyelesaikan masalah ambiguitas pada tagging dengan menggunakan korpus yang dilatih untuk menghitung probabilitas dari sebuah kata yang dengan tag yang diberikan dalam sebuah konteks.
Beberapa pendekatan yang dapat digunakan untuk tagging diantaranya adalah HMM tagger dan transformation based tagger atau sering disebut sebagai Brill tagger dengan mengkombinasikan kedua ke-2 jenis tagger sebagaimana sudah dijelaskan di atas.
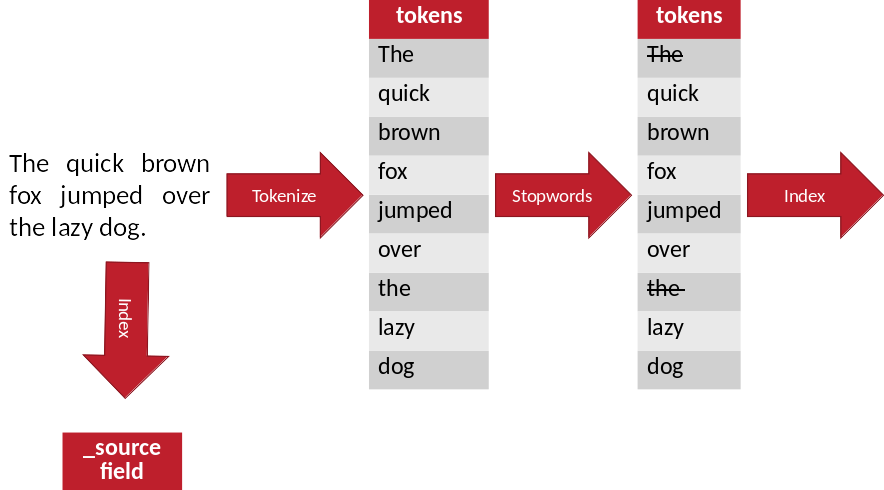
2. Tokenization
Tokenizing adalah proses pemisahan teks menjadi potongan-potongan yang disebut sebagai token untuk kemudian di analisa. Kata, angka, simbol, tanda baca dan entitas penting lainnya dapat dianggap sebagai token. Didalam NLP, token diartikan sebagai “kata” meskipun tokenize juga dapat dilakukan pada paragraf maupun kalimat

3. Stop Word Removal
Filtering adalah tahap mengambil kata-kata penting dari hasil token dengan menggunakan algoritma stoplist (membuang kata kurang penting) atau wordlist (menyimpan kata penting).
Stopword adalah kata umum yang biasanya muncul dalam jumlah besar dan dianggap tidak memiliki makna. Contoh stopword dalam bahasa Indonesia adalah “yang”, “dan”, “di”, “dari”, dll. Makna di balik penggunaan stopword yaitu dengan menghapus kata-kata yang memiliki informasi rendah dari sebuah teks, kita dapat fokus pada kata-kata penting sebagai gantinya.
Contoh penggunaan filtering dapat kita temukan pada konteks mesin pencarian. Jika permintaan pencarian anda adalah “apa itu pengertian manajemen?” tentunya anda ingin sistem pencarian fokus pada memunculkan dokumen dengan topik tentang “pengertian manajemen” di atas dokumen dengan topik “apa itu”. Hal ini dapat dilakukan dengan mencegah kata dari daftar stopword dianalisa.
4. Lemmatization dan Stemming
Stemming adalah proses menghilangkan infleksi kata ke bentuk dasarnya, namun bentuk dasar tersebut tidak berarti sama dengan akar kata (root word). Misalnya kata “mendengarkan”, “dengarkan”, “didengarkan” akan ditransformasi menjadi kata “dengar”.
Idenya adalah ketika anda mencari dokumen “cara membuka lemari”, anda juga ingin melihat dokumen yang menyebutkan “cara terbuka lemari” atau “cara dibuka lemari” meskipun terdengar tidak enak. Tentunya anda ingin mencocokan semua variasi kata untuk memunculkan dokumen yang paling relevan.
Berikut adalah contoh dari Stemming :

Contoh penerapan Natural Language Processing
Tanpa kita sadari bahwa NLP ini sudah di terapkan di dalam kehidupan kita sehari hari. tentunya dengan bantuan alat dengan teknologi yang canggih. berikut adalah beberapa contoh nya :
1. Autocorrect
Pasti di gadget kalian ada fitur autocorrect ketika dalam mengetik ada typo atau kesalahan kata, nah Autocorrect memungkinkan perangkat untuk memprediksi kata-kata yang akan diketik oleh penggunanya. Contohnya, jika kamu tidak sengaja menulis “tdiak”, fitur ini pasti akan otomatis membetulkannya menjadi “tidak”. Nah, dari mana autocorrect tahu kata mana yang perlu diperbaiki? Jawabannya tentu NLP. Karena, fitur ini dapat mempelajari kata-kata yang penulisannya benar dan salah. Sehingga, ketika autocorrect menemukan kata yang berada di luar “kamus”-nya, kata tersebut akan langsung dikoreksi.
2. Spam Email
Kalian mungkin pernah mendapatkan email yang tidak jelas yang masuk ke dalam inbox email kalian baik lowongan kerja yang tidak jelas, promosi yang tidak jelas dan informasi yang mencurigakan lainnya. Nah dengan Natural Language Processing, cara kerjanya nya adalah menganalisis seluruh konten pada email tersebut dimulai dari pengirim, judul dan isinya. Jika di dalamnya terdeteksi ada pesan dari Facebook atau Instagram, berarti kemungkinan besar pesannya akan dimasukkan ke kotak Social.
Atau, jika pesannya berasal dari alamat email tak dikenal dan isinya pun mengandung kata-kata dan link yang mencurigakan, kemungkinan besar pesannya akan mendapat tag Spam
3. Mesin Penerjemah
Siapa yang tidak mengenal google translate? yang kegunaan nya bisa membantu kita dalam segala hal apapun seperti contoh sederhananya, membuat tugas, membuat teks inggris biar terlihat jago bahasa inggris atau buat puisi dengan bahasa inggris untuk gombal dan membalas teman virtual kita di game online yang berbeda negara. Walaupun terjemahannya belum sepenuhnya sempurna, tapi setidaknya output yang dihasilkan sudah jauh lebih baik. Dengan terus berkembangnya ilmu kecerdasan buatan seperti NLP, mesin tak lagi sekadar menerjemahkan kata per kata. Tapi, juga melihat makna katanya di dalam kalimat.
4. Chat Bot
Chatbot merupakan salah satu teknologi yang sangat mengandalkan NLP. Hal ini wajar, mengingat chatbot harus mampu memahami kalimat manusia agar bisa memberikan jawaban yang tepat. Contoh sederhana nya toko official yang bisa membuat fitur chat bot agar bisa membalas calon pembeli setiap saat ketika admin sedang dalam keadaan tidak online. atau di youtube, seorang youtuber membuat sebuah chatbot untuk membuat jawaban secara otomatis semisal rumah dimana, umur berapa dan yang lainnya. ketika viewer chat bot yang otomatis langsung membalas, tanpa harus youtuber nya itu membalas satu persatu.
5. Voice Assistant
Kalian pasti sudah tidak asing dengan fitur speech to text di handphone canggih kalian. ketika kalian malas mengetik dengan google, kalian tinggal bilang "Lokasi makanan terdekat" lalu google akan langsung menampilkan hasilnya secara sangat cepat. Nyatanya, NLP sangat berkaitan erat dengan fitur ini. Karena, ketika perangkat voice recognition sedang merekam suara, nanti suaranya akan dikonversi menjadi kata. Lalu, kata yang diperoleh baru diidentifikasi maknanya oleh NLP.
6. Analisis Sentimen Media Sosial
Analisis sentimen yang dilakukan oleh NLP dapat membantu kamu memahami lebih dalam bahasa yang digunakan pelanggan dalam posting media sosial, tanggapan, ulasan, serta lainnya. Dengan begitu, kamu dapat lebih mudah mengarahkan proses design, kampanye dan lainnya.
Sekian untuk materi dari Pengenalan Natural Language Processing, harapan nya adalah materi mudah di mengerti. mohon maaf bila mana ada salah penyampaian kata atau penjelasan materi. sampai bertemu di artikel selanjutnya, adios..
إرسال تعليق